GROUP BY에는 ALIAS를 사용하지 못한다.
-> SELECT문이 처리 순서가 가장 마지막이기 때문에
: WHERE -> GROUP BY -> HAVING
-> 처리 속도를 위해 불필요한 조건들은 WHERE절에서 제외시키는 것이 좋다.
계층형 쿼리
계층형 질의
| 가상 칼럼 | 설명 |
| LEVEL | 루트 데이터이면 1, 그 하위 데이터이면 2. 리프 데이터까지 1씩 증가한다. |
| CONNECT_BY_ISLEAF | 전개 과정에서 해당 데이터가 리프 데이터이면 1, 그렇지 않으면 0 |
| CONNECT_BY_ISCYCLE | 전개 과정에서 자식을 갖는데, 조상으로 존재시 1, 그렇지 않으면 0. 여기서 조상은 자신으로부터 루트까지 경로에 존재하는 데이터 CYCLE 옵션 사용시에만 사용 가능 |
| 함수 | 설명 |
| SYS_CONNECT_BY_PATH | 루트 데이터부터 현재 전개할 데이터 까지 경로 표시 SYS_CONNECT_BY_PATH(칼럼, 경로분리자) |
| CONNECT_BY_ROOT | 현재 전개할 데이터의 루트 데이터 표시 [단항 연산자] CONNECT_BY_ROOT 칼럼 |
| 부모와 자식 관계 | 설명 |
| CONNECT BY PRIOR 자식 = 부모 | 관리자 -> 사원 방향을 전개 순방향 전개 |
| CONNECT BY 부모 = PRIOR 자식 | |
| CONNECT BY PRIOR 부모 = 자식 | 사원 -> 관리자 방향을 전개 역방향 전개 |
| CONNECT BY 자식 = PRIOR 부모 |
SELECT LEVEL, LPAD(' ', 4 * (LEVEL-1)) || 사원 사원,
관리자, CONNECT_BY_ISLEAF ISLEAF
FROM 사원 START WITH 관리자 IS NULL
CONNECT BY PRIOR 사원 = 관리자;LEVEL 사원 관리자 ISLEAF
----- -------- ----- ------
1 A 0
2 B A 1
2 C A 0
3 D C 1
3 E C 1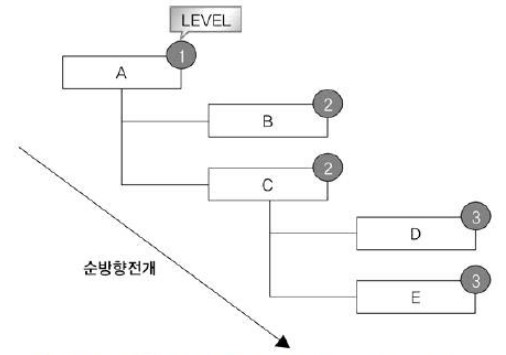
SELECT LEVEL, LPAD(' ', 4 * (LEVEL-1)) || 사원 사원,
관리자, CONNECT_BY_ISLEAF ISLEAF
FROM 사원 START WITH 사원 = 'D'
CONNECT BY PRIOR 관리자 = 사원;LEVEL 사원 관리자 ISLEAF
----- -------- ----- ------
1 D C 0
2 C A 0
3 A 1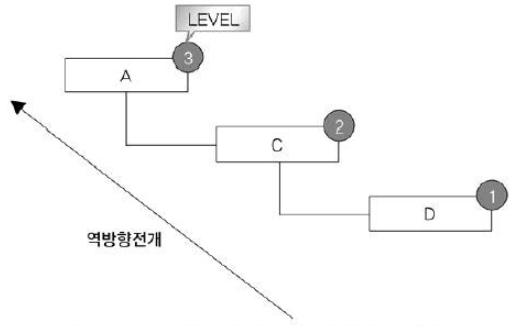
| START WITH 칼럼 [='~' | IS NULL] | 상하 관계 질의 시작 칼럼 설정 |
| CONNECT_BY_LEVEL | 연속된 숫자 조회시 사용 |
--1~10까지 연속된 숫자 조회
SELECT LEVEL AS NO
FROM DUAL
CONNECT BY LEVEL <=10--2021년 1월부터 12월까지 출력
SELECT '2020 년 '||LPAD(LEVEL, 2, 0)||'월' AS NO
FROM DUAL
CONNECT BY LEVEL <=12--특정 날짜 구간으로 조회
SELECT TO_DATE('20200701', 'YYYYMMDD') + (LEVEL-1) AS DT
FROM DUAL CONNECT BY LEVEL <= (TO_DATE('20200717', 'YYYYMMDD') - TO_DATE('20200701', 'YYYYMMDD')) + 1
---------------------------------------------------------------------------------------------
WITH WD AS
( SELECT TO_DATE('20200701', 'YYYYMMDD')
AS FROM_DT -- 시작일자 ,
TO_DATE('20200717', 'YYYYMMDD') AS TO_DT -- 종료일자
FROM DUAL )
SELECT DT, DT2
FROM ( SELECT TO_CHAR(FROM_DT + (LEVEL-1), 'YYYYMMDD') AS DT ,
TO_CHAR(FROM_DT + (LEVEL-1), 'YYYY-MM-DD') AS DT2
FROM WD CONNECT BY LEVEL <= (TO_DT - FROM_DT) + 1 )--데이터 복제 [카테시안 곱 이용]
SELECT Y.NO, X.*
FROM(
SELECT *
FROM EMP e
)X, (
SELECT LEVEL AS NO
FROM DUAL
CONNECT BY LEVEL<=2
)Y
ORDER BY ENAME,JOB,NO
CASE문과 DECODE
DECODE와 CASE의 특징
DECODE(RAW,'%법','1','2') -> DECODE로는 LIKE 불가능
-> CASE WHEN RAW LIKE '%법' TEHN '1' ELSE '2'
THEN 결과 값 앞에 이어 붙이거나 공백을 넣고 싶을땐
-> CASE WHEN RAW LIKE '%법' THEN ' '||'1' ELSE '2' ||
SELECT ANIMAL_ID, NAME,
CASE WHEN SEX_UPON_INTAKE LIKE 'Neutered%' OR SEX_UPON_INTAKE LIKE 'Spayed%' THEN 'O'
ELSE 'X'
END AS 중성화
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
무슨 서브쿼리를 써야할까?
1. 선수들 중 포지션이 미드필더인 선수들의 소속팀명 및 선수 정보 출력
2. 선수 정보와 해당 선수가 속한 팀의 평균 키 함께 출력
3. 평균키가 삼성 블루윙즈팀의 평균키보다 작은 팀의 이름과 해당 팀의 평균키 출력
1. 인라인뷰 (FROM절 서브쿼리)
2. 스칼라 서브쿼리 (SELECT절 서브쿼리)
3. HAVING 서브쿼리
1. SELECT절 서브쿼리 -> 스칼라 서브쿼리 (1로우 1칼럼)
2. FROM절 서브쿼리 -> 인라인뷰 (임시로 생성되는 동적 뷰로 조인과 같은기능)
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM (SELECT PLAYER_NAME, POSITION, BACK_NO, HEGIHT)
FROM PLAYER
WHERE HEIGHT IS NOT NULL
ORDER BY HEIGHT DESC)
WHERE ROWNUM<=5;-> 같은 키인 선수가 존재해도 5명이 넘어가면 미출력 -> RANK() 함수 이용
3. HAVING 서브쿼리 -> 그룹핑된 결과에 대한 부가적인 조건
SELECT P.TEAM_ID 팀코드, T.TEAM_NAME 팀명, AVG(P.HEIGHT) 평균키
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID
GROUP BY P.TEAM_ID, T.TEAM_NAME
HAVING AVG(P.HEGIHT) < (SELECT AVG(HEIGHT)
FROM PLAYER
WHERE TEAM_ID='K02');
1. 고양이와 개는 몇 마리 있을까
-- 코드를 입력하세요
SELECT ANIMAL_TYPE, COUNT(ANIMAL_TYPE)
FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE
ORDER BY ANIMAL_TYPE ASC
2. 동명 동물 수 찾기
-- 코드를 입력하세요
SELECT NAME, COUNT(NAME)
FROM ANIMAL_INS
GROUP BY NAME
HAVING COUNT(NAME)>=2
ORDER BY NAME
4. 입양 시각 구하기 (1)
(1) 인라인뷰에서 처리 후, 해당 조건의 출력만 수행
SELECT hour, COUNT(*)
FROM
(
SELECT TO_NUMBER(TO_CHAR(datetime,'HH24')) as hour
FROM ANIMAL_OUTS
)
WHERE hour BETWEEN 9 AND 19
GROUP BY hour
ORDER BY hour;
(2) SELECT문이 가장 마지막으로 처리하므로, ALIAS사용 못해서 각각 시간변환 필요
SELECT to_char(datetime, 'HH24') as hour, count(*)
FROM ANIMAL_OUTS
where to_char(datetime, 'HH24') between 09 and 19
group by to_char(datetime, 'HH24')
order by hour
5. 입양 시각 구하기 (2)
보호소에서는 몇 시에 입양이 가장 활발하게 일어나는지 알아보려 합니다.
0시부터 23시까지, 각 시간대별로 입양이 몇 건이나 발생했는지 조회하는 SQL문을 작성해주세요.
이때 결과는 시간대 순으로 정렬
-> 계층형 쿼리 필요 [0시부터 23시를 만들어야 한다]
| HOUR | COUNT |
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| 5 | 0 |
| 6 | 0 |
| 7 | 3 |
| 8 | 1 |
| 9 | 1 |
| 10 | 2 |
| 11 | 13 |
| 12 | 10 |
| 13 | 14 |
| 14 | 9 |
| 15 | 7 |
| 16 | 10 |
| 17 | 12 |
| 18 | 16 |
| 19 | 2 |
| 20 | 0 |
| 21 | 0 |
| 22 | 0 |
| 23 | 0 |
정답
SELECT HOUR, COUNT(*)-1 COUNT
FROM
(
(SELECT TO_NUMBER(TO_CHAR(DATETIME, 'HH24')) HOUR FROM ANIMAL_OUTS)
UNION ALL
(SELECT LEVEL-1 FROM DUAL CONNECT BY LEVEL <=24)
)
GROUP BY HOUR
ORDER BY HOUR
(0) 계층형쿼리 + 외부조인
SELECT A.HOUR, COUNT(B.DATETIME) AS COUNT
FROM (SELECT LEVEL-1 AS HOUR
FROM DUAL
CONNECT BY LEVEL <=24) A
LEFT JOIN
ANIMAL_OUTS B
ON A.HOUR = TO_NUMBER(TO_CHAR(B.DATETIME,'HH24'))
GROUP BY A.HOUR
ORDER BY A.HOUR
다른 풀이들
(1) WITH문으로 계층형쿼리를 만들고, TO_CHAR로 시간을 가져온다.
WITH A AS(
SELECT LEVEL-1 AS HOUR
FROM DUAL
CONNECT BY LEVEL <= 24
),
B AS(
SELECT TO_CHAR(DATETIME, 'HH24') AS HOUR
FROM ANIMAL_OUTS
)
SELECT A.HOUR AS HOUR, COUNT(B.HOUR) AS COUNT
FROM A,B
WHERE A.HOUR = B.HOUR(+)
GROUP BY A.HOUR
ORDER BY A.HOUR
(2) 가상테이블 이용
SELECT T.HOUR,
(SELECT COUNT(*)
FROM ANIMAL_OUTS
WHERE T.HOUR = TO_CHAR(DATETIME, 'HH24'))AS COUNT
FROM
(SELECT LEVEL-1 AS HOUR
FROM DUAL
CONNECT BY LEVEL <= 24)T
(3) DECODE 이용
SELECT LVL,
SUM(DECODE(SUBSTR(COUNT,0,2),LVL,SUBSTR(COUNT,3),0)) COUNT
FROM
(SELECT TO_CHAR(DATETIME,'HH24')||COUNT(*) COUNT
FROM ANIMAL_OUTS
GROUP BY TO_CHAR(DATETIME,'HH24')) A,
(SELECT LEVEL-1 LVL
FROM DUAL
CONNECT BY LEVEL <= 24) B
GROUP BY LVL
ORDER BY LVL;
(4) WITH문과 외부 조인
with tmp as (
select level-1 as hour
from dual
connect by level < 25
)
select a.hour
, nvl(b.count, 0)
from tmp a
left outer join
(
select to_char(datetime, 'HH24') as hour
, count(*) as count
from animal_outs
group by to_char(datetime, 'HH24')
) b
on a.hour = b.hour
order by a.hour
;
(5) CASE문 이용
SELECT VT.HOUR, CASE WHEN CT.COUNT IS NULL THEN 0 WHEN CT.COUNT IS NOT NULL THEN CT.COUNT END COUNT
FROM (--카운팅
SELECT TO_CHAR(DATETIME, 'HH24') HOUR, COUNT(TO_CHAR(DATETIME, 'HH24')) COUNT
FROM ANIMAL_OUTS
GROUP BY TO_CHAR(DATETIME, 'HH24')
) CT,
(--가상테이블
SELECT LEVEL-1 HOUR
FROM DUAL
CONNECT BY LEVEL <= 24
) VT
WHERE VT.HOUR = CT.HOUR(+)
ORDER BY VT.HOUR;
'Data Science > SQLP' 카테고리의 다른 글
| [프로그래머스] 5. JOIN (0) | 2022.03.07 |
|---|---|
| [프로그래머스] 4. IS NULL (0) | 2022.03.07 |
| [프로그래머스] 2. SUM, MAX, MIN (+ 누적합계) (0) | 2022.03.07 |
| [프로그래머스] 1.SELECT (0) | 2022.03.07 |
| [Oracle] 1. SELECT문 처리과정 (0) | 2022.02.06 |