1. 데이터 그룹 분석
집계함수 사용
groupby함수
그룹 분석 공식
1. 범주형 변수로 그룹 연산 기준을 선정
2. 범주형을 기준으로 연속형을 묶는다.
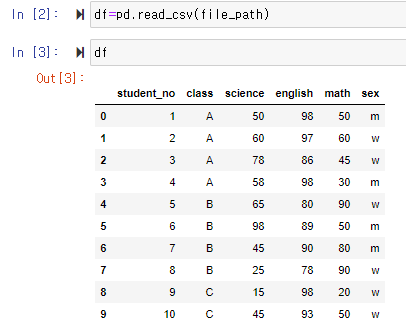
-> 사용할 데이터 불러오기
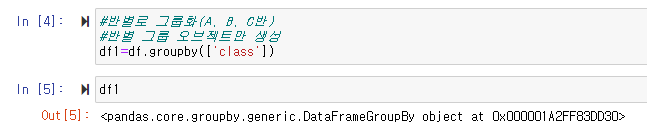
-> 사용할 범주형 데이터 선정

-> get_group : 선택한 범주형 데이터중 하나의 데이터를 선정
-> groupby(['범주형','범주형']).mean() : 범주형 데이터와 범주형 데이터의 그룹
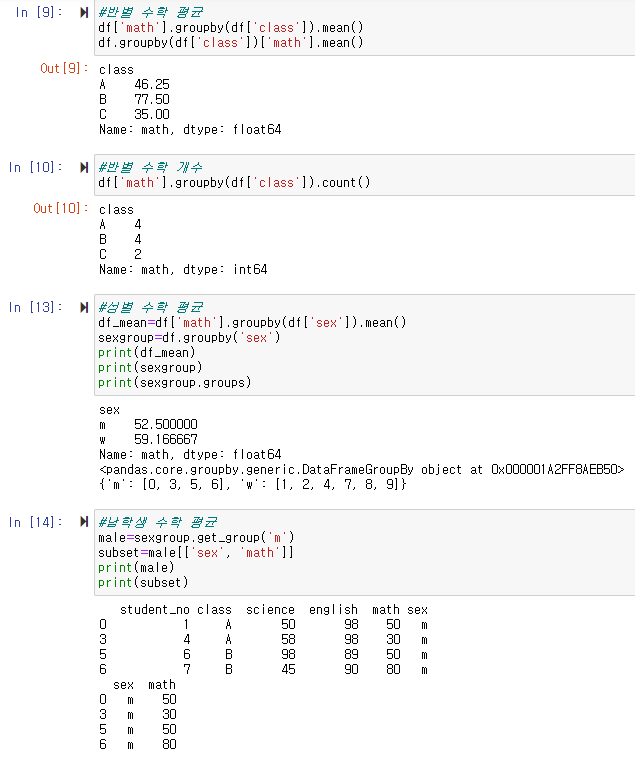
-> df['연속형'].groupby(df['범주형']).함수() :범주형 중 연속형의 함수
-> df.groupby(df['범주형'])['연속형'].함수() 범주형 중 연속형의 함수 => 같은 구문
-> df['math'].groupby(df['class']).mean() 반별 수학 평균

df['math'].groupby(df['sex']).mean() 성별 수학 평균
->성별만을 그룹함수로
-> sexgroup = df.groupby('sex')
male=sexgroup.get_group('m') 남학생 수학 평균
-> 성별의 그룹함수로 그룹
->subset=male[['sex', 'math']]
2. 데이터 재구조화 :
분석과정에서 원본 데이터 구조가 분석기법에 맞지 않아 행과 열의 위치를 바꾸거나, 특정요인에 따라 구조를 바꿀때
- 데이터 구간화
- 원-핫인코딩
- 데이터 전치
- 피봇 테이블
- 열, 행 전환
- 행, 열 인덱스 전환
-
데이터 구간화
-
연속형을 범주형으로
-
pd.cut() : 동일 길이로 나누기
-
pd.qcut() : 동일 개수로 나누기
-
-

-> 수학 변수에 대해 3개의 동일한 구간 길이 : [(19.93, 43.333] < (43.333, 66.667] < (66.667, 90.0]]

-> 수학 변수에 3개의 구간 범주를 추가 후 각 범주의 특성을 찾는다.

-> 실수 값을 카테고리 값으로 변환하기
[qcut : 구간의 경계를 지정하지 않고 각 구간마다 속해있는 데이터 개수를 같게 나눈다.]
pd.qcut(실수 데이터, 나눌 그룹 개수, 각 그룹의 라벨)

-
원-핫인코딩:
머신러닝 알고리즘을 위해 데이터를 변환하는데 범주형 데이터를 원-핫인코딩 형태로 변환한다.
[하나의 데이터만 1로 변경하고 나머지는 0으로 변경하는 과정]

-> 해당하는 것에 1, 해당하지 않으면 0
-
데이터 전치:
데이터 프레임 행과 열의 기준(축)을 바꾸는 방법


-
피봇 테이블:
많은 양의 데이터에서 필요한 자료만을 뽑아 새롭게 데이터를 재구성
[원하는 대로 데이터를 정렬하고 필터링할 수 있다.]
-> 데이터 열 중 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용해 데이터를 조회하여 펼쳐 놓는다.
pd.pivot_table(데이터프레임 이름,행 인덱스로 사용할 열 이름, 열 인덱스로 사용한 열 이름, 데이터로 사용할 열 이름)
-> 두 열을 인덱스로 바꾼 후, 각각의 인덱스의 라벨 값이 키의 값과 같은 데이터를 찾아서 해당 칸에 삽입한다.
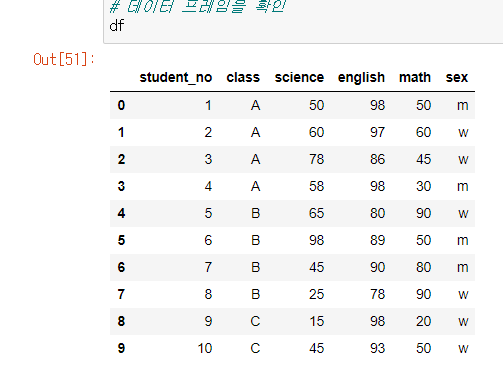

-
멜트 :
열을 행으로 변경하는 재구조화 과정. -> 열이 행으로 흘러 열이 짧아지고 행이 길어진다.
-> 여러 열의 이름을 'variable'컬럼을 위에서 아래로 길게 쌓고, 'value'컬럼에 ID와 variable에 해당하는 값을 추가
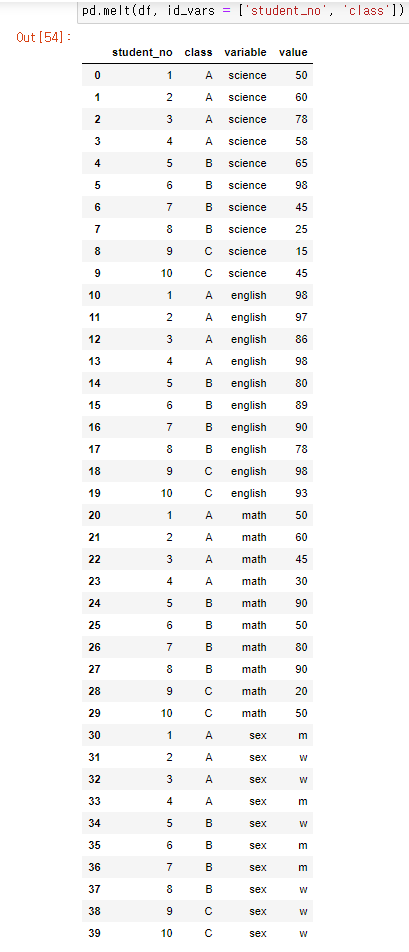
-> 'student_no'와 'class'를 기준으로 나머지 컬럼을 밑으로 추가한다
-
스택/언스택:
행 인덱스와 열 인덱스 교환시 사용하는 기능
-> 스택 : 열이 행으로 [열 인덱스가 반시계 방향으로 90도 회전]
-> 언스택 : 행이 열로 [행 인덱스가 시계 방향으로 90도 회전]
-> 문자열 이름과 순서를 표시하는 숫자 인덱스를 모두 사용 가능

'Computer Engineering > Big Data Analytics Using Python' 카테고리의 다른 글
| [빅데이터 분석 프로젝트] 마크다운으로 팁 데이터 분석 보고서 작성하기 -Part 2 (0) | 2021.04.19 |
|---|---|
| [빅데이터 분석] 10minutes pandas (1) (0) | 2021.04.17 |
| [빅데이터 분석 프로젝트] 마크다운으로 따릉이 데이터 분석 보고서 작성하기 -Part 1 (0) | 2021.04.06 |
| [에러잡기] UnicodeDecodeError가 뜰 때 (0) | 2021.04.06 |
| [빅데이터 분석 프로젝트] 마크다운으로 팁 데이터 분석 보고서 작성하기 -Part 1 (0) | 2021.04.06 |

